


Every engineer wants to ship high-quality software systems, but the “how” isn’t always...

Every engineer wants to ship high-quality software systems, but the “how” isn’t always straightforward. To help, we designed a testing series, “Shipping code quickly with confidence.” Using code from sendsecure.ly, a Basis Theory lab project, readers will bring together the testing layers and strategies used by our data tokenization platform to achieve its 0% critical and major defect rate. You can find the links to all published articles at the bottom of each blog.
In the first installment of our “Shipping code quickly with confidence” series, we reviewed the various testing layers and principles we use at Basis Theory. This post goes deep into our approach to API Acceptance and Integration Tests, including links to a sample application to see everything come together!
Acceptance Tests
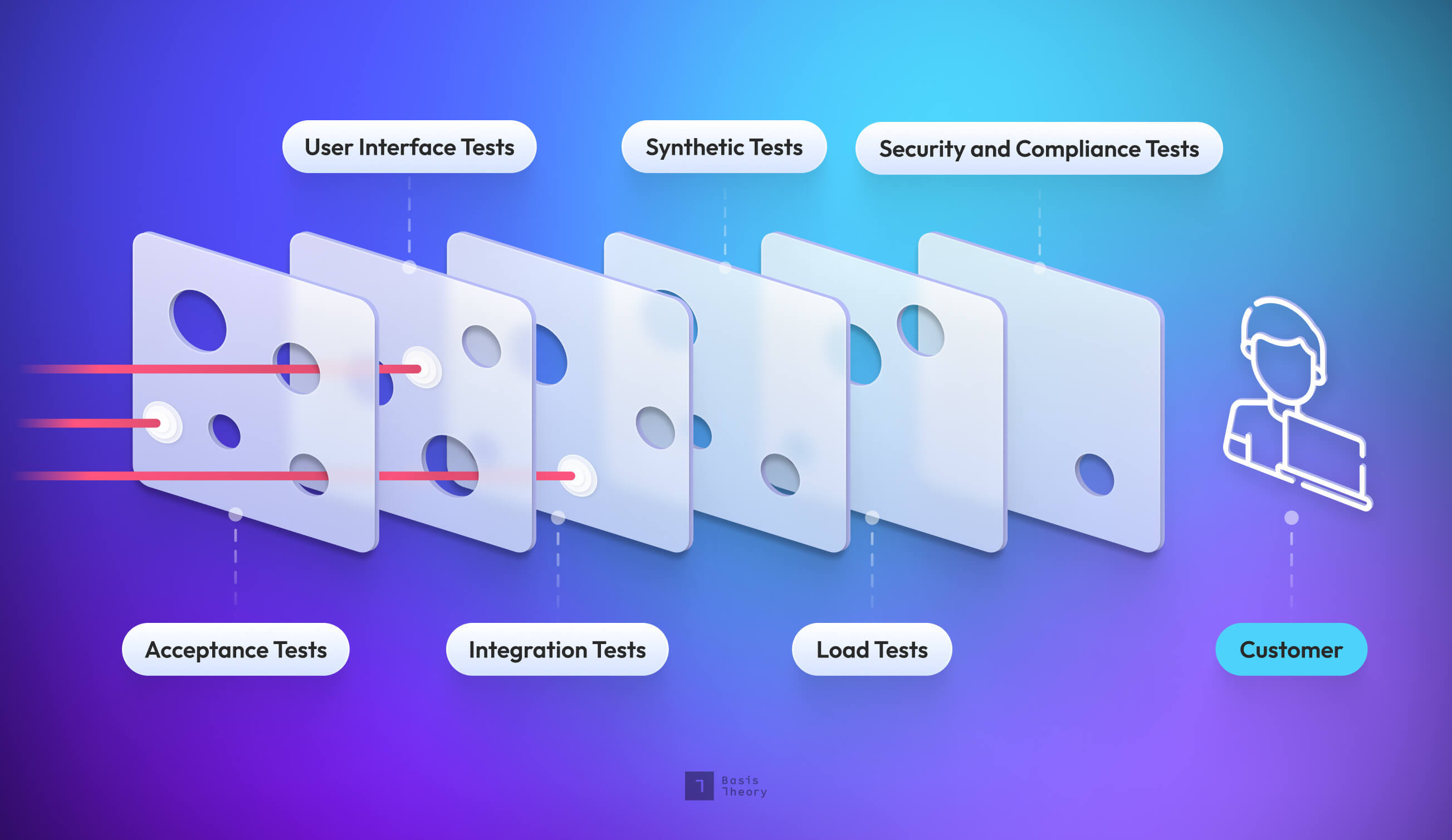
Our approach differs from traditional testing strategies, where unit tests are often the foundation of the swiss cheese model. Instead, we spend the most time writing Acceptance Tests against our systems. This gives us the fastest feedback loops in our development workflows. Unit tests are great for verifying business logic in methods and classes, but they are tightly coupled to the implementation, which inhibits our ability to refactor the implementation without also modifying the tests. Focusing on “black-box” Acceptance Tests against our applications results in high cohesion, allowing us to refactor the code without modifying the tests.
It’s not that we don't write any unit tests; unit tests just aren’t our primary tool.
What does an Acceptance Test cover?
To understand what an Acceptance Test covers, we have to first understand its boundaries. Acceptance Tests should treat the system under test (SUT) as a black box. In other words, the test should only rely on the public interfaces exposed by the SUT. When we test a RESTful API, the test should only interact with the API via HTTP requests and responses, asserting that the request and response satisfy the acceptance criteria.
Acceptance Tests cover a single unit of work or action that can be taken against the SUT. When testing an API, a unit of work would be a single HTTP request/response. Acceptance Tests focus on the behavior of a system rather than the implementation of a system. The term Behavior Driven Development (BDD) comes from this approach. A traditional unit test may look something like the following:
An Acceptance Test verifying the same behavior could be:
Note that both the unit test and Acceptance Test assert the same behavior. However, the two differ in that the unit test asserts how the result was produced while the Acceptance Test only asserts the correct result was produced based on the scenario.
“Mocking” application boundaries in Acceptance Tests
When writing unit tests, mocking is necessary for any external dependency (e.g., filesystem, API, database). This doesn’t change when writing Acceptance Tests, we just have a few more options at our disposal. Instead of mocking a library or interface as we would in a unit test, Acceptance Tests move the test boundary to the edges of the application. External dependencies (the “edges”) need to be mocked (or not mocked) so the Acceptance Tests can run in isolation with complete control.
Mock servers
Rather than mocking an HTTP client to avoid making a network request, our application runs in “acceptance” mode, where we configure the same HTTP client to make requests to a mock server controlled by the Acceptance Test. Mocking an external dependency can be done in various ways. Tools like Wiremock allow us to stub API requests and responses to easily mimic happy and sad-path scenarios.
Test the specification
Often, the external dependency is an implementation of a specification like OAuth 2.0, OpenID Connect, or JMS. In these scenarios, we leverage open-source tools, such as IdentityServer, that implement the specification rather than trying to emulate the actual provider.
Docker
A majority of open-source tools also publish Docker images to a public registry. Docker images make exceptional candidates for creating ephemeral environments; especially for data storage tools such as MSSQL, Redis, and MongoDB.
At Basis Theory, we leverage all of the above alongside Docker Compose to stand up an ephemeral environment on our local machines that we can run Acceptance Tests against. We use the same commands to verify our systems locally and in our CI/CD pipeline.
Acceptance Test structure
Each test, regardless of strategy, consists of three sections: Arrange, Act, and Assert. In BDD-speak, these terms are commonly referred to as Given, When, Then. Arrange is the setup portion of the test, Act is the action being taken, and Assert is the verification(s) that the actual behavior observed aligns with our expectations. Each test follows this layout to improve readability and troubleshooting of failing tests. To further improve the readability and findability of tests, we consistently do the following:
Specific and verbose test names
.jpeg)
Group like-tests together
.jpeg)
Acceptance Tests feedback loops
So far, we’ve established the content and structure of Acceptance Tests, but writing Acceptance Tests doesn’t provide value on its own. To get the full value of Acceptance Tests we have to run them against the system under test to create feedback loops. We run Acceptance Tests at multiple points in the SDLC to provide meaningful feedback loops to detect bugs, regressions, and flakiness.
Local Development
The fastest feedback loop is running the application on your local workstation when developing a new feature. We make use of Make (punny, I know) to run scripts that:
- Build the application
- Start and configure an ephemeral environment with dependencies
- Run Acceptance Tests
Through the use of one command, make verify, we create an ephemeral environment and run all of our Acceptance Tests on our local workstation in minutes!
Pull Requests
Opening a pull request to the repository's default branch kicks off our CI pipeline. Thanks to automation, our pipeline uses the same make verify command to verify the code. The consistency between local development and our CI pipeline enables us to troubleshoot any failures in the pipeline without having to push new code.
Merge to Default Branch
Running unit and/or Acceptance Tests after merging to the default branch is a debatable topic. Re-running these tests depends on how the CI/CD pipeline works. If merging to the default branch promotes an immutable artifact built from the pull request workflow, re-running these tests may be redundant and costly. However, if merging to the default branch creates a new artifact, you should rerun the tests as there could be changes in the newly built artifact. Status checks and requirements in the CI/CD pipeline also play a factor. If the pipeline doesn’t require Acceptance Tests to pass before merging to the default branch, then Acceptance Tests need to be run at some point before deploying to a live environment.
Integration Tests
The next layer of our swiss cheese model is Integration Tests. Integration Tests are similar to Acceptance Tests in that they treat the system under test (SUT) as a black box and only interact with the SUT through the public interface. However, Integration Tests differ from Acceptance Tests in that they run against a deployed environment, typically a development or staging environment. These tests verify that we configured the system to correctly communicate with external dependencies (e.g., filesystem, API, database).
The environment that these tests run against should be as identical to production as possible. Thanks to tooling that enables Infrastructure as Code (IaC), creating repeatable environments and infrastructure is as simple as ever.
To verify connectivity with external dependencies, we need to create Integration Tests to verify scenarios that depend on these external dependencies. At Basis Theory, we focus our API integration tests on the entire lifecycle of a resource. For example, we test that Applications can be created, read, updated, and deleted through the appropriate API endpoints.
Configurable Integration Tests
While test configuration isn’t specific to Integration Tests, we can find the most value in configurable Integration Tests to enable faster feedback loops and debugging of Integration Tests. Integration tests should be configurable to run against any environment. Without the ability to configure integration tests to point at a local environment, we have no way to verify the tests work without merging them to our default branch and letting them run via automation.
Feedback Loops with Integration Tests
So far, we’ve established the focus and configurability of Integration Tests, but when do we run Integration Tests to provide the best feedback loops?
After every deployment
After each deployment to our Development environment, our CI/CD pipeline runs the full suite of Integration Tests. If a single test fails, the pipeline halts and blocks the promotion of the artifact to higher environments (e.g., Production).
On-demand
Since we can configure our Integration Tests to point at any environment we have access to, we can also run these tests whenever we like. We can run Integration Tests from our local machine against a deployed Development environment or target a local ephemeral environment. This flexibility dramatically improves the developer experience when writing new tests or debugging a flaky test.
Pulse check: Confidence level
The goal of any test is to add confidence that the code, application, or system behaves as expected. So far, we’ve covered acceptance and Integration Tests, but how confident are we in our testing pyramid?
Are we confident that the application’s programmable interface does what we expect? Yes, the API Acceptance Tests provide this confidence by validating the system's behavior across various happy and sad-path scenarios.
Are we confident that the application can communicate with external dependencies? Yes, API Integration Tests provide confidence that our application can communicate and receive traffic from external dependencies in a deployed environment. E2E Integration tests cover the systems as a whole, replicating user behavior in a production-like environment.
Are we confident that the application’s user interface does what we expect? Not yet.
Are we confident that the application is always available? Nope. Not yet.
Are we confident that the application can handle production throughput and beyond? Uh uh, not yet.
Are we confident that the application is free of security vulnerabilities? Also, not yet.
Are we confident that the application is secure against common attack vectors (e.g., OWASP)? Not yet.
Don't worry. By the end of this series, "Yes" will be the answer to all of the above questions. So stay tuned for our upcoming posts on the remaining testing layers, when to use them, and how they add confidence to our SDLC!
- Testing Layers and Principles
- API Acceptance and Integration Testing
- UI Acceptance and End-to-End Testing
- Synthetic Testing
- Load Testing
- Security and Compliance Testing
Have questions or feedback? Join the conversation in our Slack community!




