-Dec-13-2022-06-27-12-2630-PM.png?width=50&name=62507e98e39fbe12913a3198_nathan-loading%20(1)-Dec-13-2022-06-27-12-2630-PM.png)

There are an estimated 1.1 million Go developers today, making Go one of the top 10 languages in...

Tokenization is only valuable to an organization if the tokens are useful. While cookie-cutter tokens with rigid properties provide great guardrails to get up-and-running quickly, they can fall short of their developers' unique needs. That's why we made our Tokens configurable, allowing developers to make the best decisions for their systems and implementation. It's this flexibility that makes Basis Theory’s Tokens so unique.
Expressions: The secret sauce
Expressions provides Basis Theory developers unmatched flexibility in configuring their tokens. Instead of being limited to a set of pre-determined functions defined by our platform, developers use the liquid syntax to programmatically and dynamically transform their tokens to fit their specific business needs. In the following sections, we’ll highlight examples of how our token properties use expressions.
Basis Theory Token Properties and Benefits
Satisfy database schemas formatting requirements with Aliasing
When you create a new token, that token receives a unique identifier (the “token ID”). Instead of storing the sensitive value in your database, you store the “token ID”. Sometimes, though, the database schema is hard to change. For example, imagine a scenario where you held a customer’s email address in plaintext and now needed to tokenize that data. This would require changing the definition of the email address column to accommodate a UUID. What if, instead, you could set the “token ID” to a unique value that looked like an email address? Welcome to Aliasing.
When creating a token, you can optionally provide the id property, which allows you to control the format of the "token ID". There are two primary options: alias_preserve_format and alias_preserve_length. This is where Expressions come in, allowing you to configure the format further. This example shows how you would create an alias in the format of an email address:
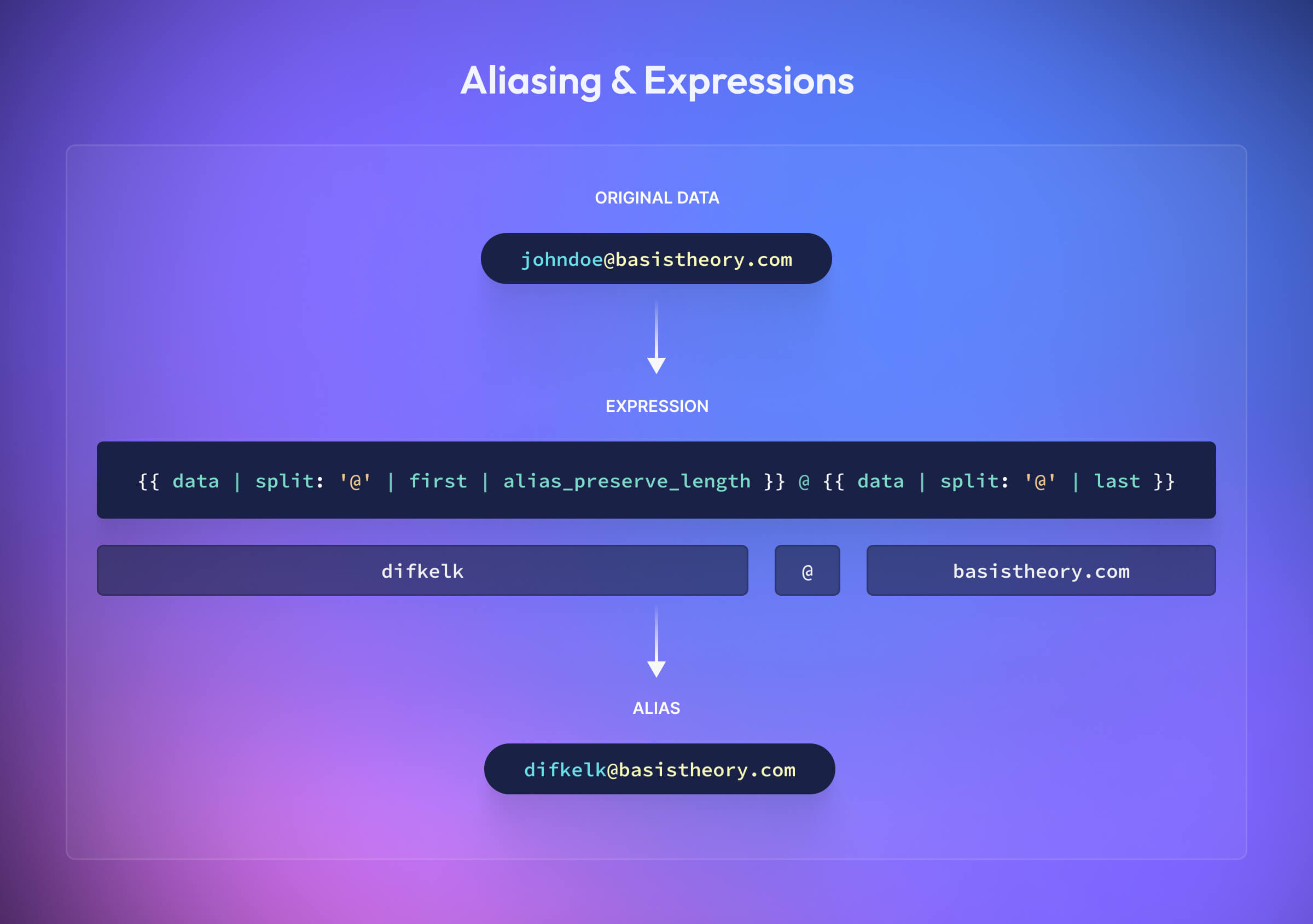
Learn more about aliasing using expressions!
Only reveal what’s needed with Masking
When reading back a token, users and systems don’t always need access to the full plaintext value. Instead, masks allow you to reveal only part of the needed sensitive data. For example, you may only need to show the last four digits to validate a credit card or social security number (SSN).
Any data in any Token Type can be masked to reveal all or part of the underlying data; however, some Token Types offer preconfigured masks based on popular use cases for that data type. For example, if you were using the social_security_number Token Type, the mask property would automatically be set to .
While using the default masks of a preconfigured Token Type may accelerate development, what if you need to change a preconfigured Token Type’s default or create your custom token? That’s where expressions can help. By changing the expression to or adding a new one, developers can mask nearly any combination of the underlying data within a token.
The possibilities are truly endless! Read more about masking using expressions!
Map to new and existing access policies with Privacy
Some tokens may reveal part or all of the underlying data, while others may be enabled for operations, like searching or deduping (we’ll get to these in a sec). We've incorporated NIST-defined impact levels to help rightsize the threat posed by a breach, classifications to define the type of data inside the token, and restriction policies to ensure only Applications with access to view data can. Combined, these elements ensure actors have the least privilege necessary.
For example, imagine a support team that regularly needs to verify a payment method the caller used to purchase a widget. To do so, the support specialist only needs the last four digits of the caller's credit card, while the billing department, which wants to process a payment, needs access to the full credit card number to process a refund. By assigning different privacy controls to the token, you can mask data for the support specialist and reveal the whole card number to the billing department.
You can learn more about the privacy settings in our comprehensive guide.
Tag your tokens with Metadata
The metadata property is a key-value pair collection that allows you to add non-sensitive data to the token. Metadata is available on every Token Type and provides a flexible way to enrich and tag your tokens. For example, you could add your customer ID to help organize and locate tokens for a specific user or tag certain tokens as falling into certain regulatory requirements, like GDPR.
Metadata tags are supported in search queries and available to all applications regardless of the privacy settings, allowing systems that don’t have access to the underlying data to have more context around the token itself.
Search sensitive data without decrypting it by adding Search Indexes
Basis Theory’s tokenization platform comes with powerful search capabilities that allow you to search over your tokenized data without needing to detokenize anything. (Behind the scenes, the sensitive data isn’t being decrypted either!) To make this work, however, the system must know some information about the shape of the token data and which pieces can be searched.
Enter the search_indexes property! When creating your token, you can provide an array of search indexes that represent the pieces of data you want to search. To continue with the SSN example, you would likely want to search for the entire number with and without the dashes, as well as just the last four digits:
You can provide as many indexes as you need to search over your data and utilize these indexes through both our Web Portal and the API. Learn more about search indexes.
Identify unique elements of your sensitive data with Fingerprints
Fingerprints provide a safe and secure way to identify a token’s uniqueness. Without it, you’d be unable to identify duplicate data in your system without detokenizing or decrypting it. Fingerprints can be used to validate that an SSN isn’t already stored in your system or link stored credit cards for a loyalty program. The fingerprint is not reversible and is safe to keep in your own database.
But, what pieces of data determine uniqueness? Sure, when comparing a simple string to another simple string, it is easy to determine whether they are the same or not. Looking back to the PII example above, it isn’t quite so easy. There are three pieces of data being tokenized: name, ssn, and account_number What makes this particular token value unique? Is it the combination of all three properties? Perhaps the account number is shared across multiple accounts so only the name and ssn are unique?
Fingerprint expressions allow you to configure what data properties determine its uniqueness.
This expression concatenates the name, ssn, and account_number values and uses the resulting value to generate the fingerprint. If you were to generate a second token with the same values for those properties, it would give you the same fingerprint as the first.
Fingerprints also power Basis Theory’s deduplication feature. If deduplication is enabled in your tenant, Basis Theory will automatically return an existing token instead of creating a new one if the fingerprint matches a current token. Learn more about all the features supported by fingerprint expressions.
Manage data with Token Expiration
Basis Theory’s platform also supports a time-to-live (TTL) capability, allowing you to expire some or all of your token data. When the token reaches its expiration date, the system automatically purges it. Using the Token Expiration can help with data retention policies that require removing data after a specific date, sharing temporary credentials, or purging expired credit cards from the system.
When creating a token, simply set the expires_at property to the date/time you want the token to expire:
Let’s recap
With Basis Theory’s tokenization platform:
- Developers can use or build off of pre-configured Token Types or configure their own
- Expressions provide Basis Theory Tokens with unmatched flexibility
- All Basis Theory Tokens can be aliased, masked, permissioned, searched, tagged, fingerprinted, and expired
- Everything is possible through our public API, removing the need to use a cumbersome UI to manage the details of every property on a token.
Want to try it for yourself? Create a free account and spin up your PCI Level 1 and SOC 2 certified environment in less than a minute—without adding a credit card.




