


Every engineer wants to ship high-quality software systems, but the “how” isn’t always...

Every engineer wants to ship high-quality software systems, but the “how” isn’t always straightforward. To help, we designed a testing series, “Shipping code quickly with confidence.” Using code from sendsecure.ly, a Basis Theory lab project, readers will bring together the testing layers and strategies used by our data tokenization platform to achieve its 0% critical and major defect rate. You can find the links to all published articles at the bottom of each blog.
This blog is the third episode in our Testing series. Previously, we covered some major aspects of software testing and dove deep into Basis Theory’s API testing practices. Now, it’s time to move to the next layer: the User Interface (UI).
In this post, we will restrict the scope to web applications, so by “UI,” we mean the browser-rendered portion of the application. And for that, we will use Cypress as a testing tool and assert the main characteristics:
- Behavior
- Responsiveness
- Accessibility
UI Acceptance Tests
At Basis Theory, acceptance tests are synonymous with Behavior-Driven Testing (BDT) when it comes to UI. With BDT, we focus on user interactions with the application rather than exhaustively verifying every technical function of the software. To achieve that, we run an isolated application instance and start interacting with it through a headless version of the browser combined with special commands, like cy.intercept. Doing so helps us keep the frontend application interactions with the external world to a minimum, including the API.
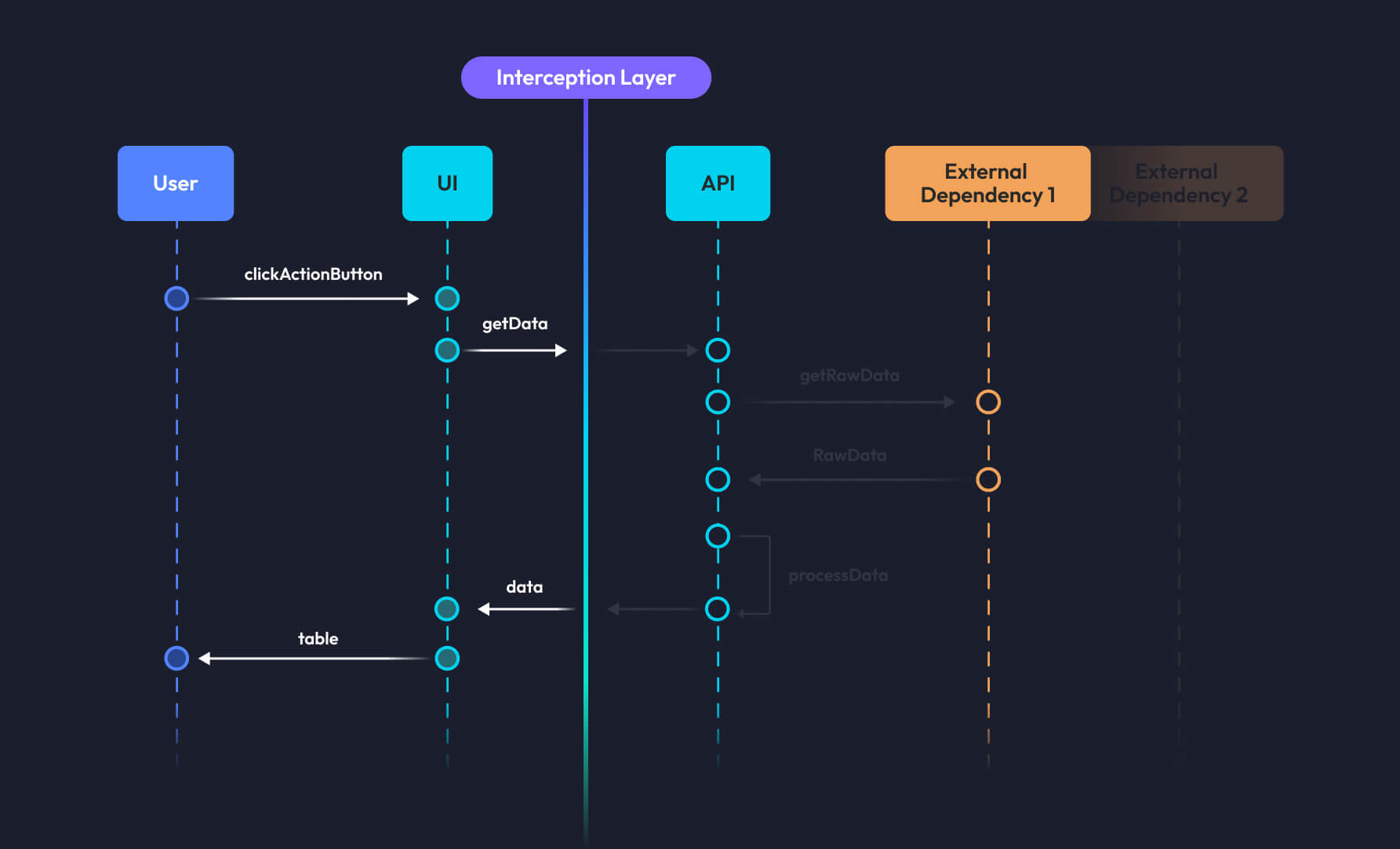
To effectively test potential user behaviors, you need to empathize with them as much as possible. Unless you designed your UI for a single person, you should consider the following when writing your tests:
- Users think differently from each other
- Users have different levels of understanding of how your application works (sometimes zero)
- Users have different needs, abilities, and devices and speak different languages
Product owners and engineers should work together to define when a system is considered stable. In other words: What sort of tests you should be writing or prioritizing?
Accessibility (A11y)
We increasingly rely on the Internet to connect us to the information, people, and work needed to make decisions, friends, and money—except when it doesn't. To create a fair and inclusive experience—one where everyone can participate—developers should consider the visual needs of their users when interacting with their website or application.
While modern frameworks automatically implement ARIA specifications to alleviate lower levels of accessibility compliance and increase A11y reporters’ grades, gaps between the application and the desired level of conformity will likely exist.
Meeting with project stakeholders to discuss accessibility guidelines and desired levels of conformity at kickoff will help align teams on design and implementation throughout development.
To find out if your pages have A11y (detectable) violations, run automated checks when the page loads or the UI state changes significantly (e.g.redirects, visual elements added to or removed from the DOM, etc). Most developers are familiar with Axe’s accessibility testing engine, which plays well with other UI testing tools, including Cypress:
In the example above, we inject Axe's script into the page as soon as it is visited, which persists through DOM updates in Single Page Applications.
Internationalization (i18n)
The first "W" in the "World Wide Web" (WWW) holds special meaning to those looking to expand their business beyond their country's borders. Internationalization is becoming a hard requirement for global organizations such as retail, supply chain, finance, insurance, etc.
Features, like automatically detecting user locale, displaying native language, and supporting internationalized routing, can be part of the framework's features or handled by the application. We can assert the behavior in both instances and not worry about implementation.
To ensure your users will get verbiage in their respective language—the ones you choose to support—you can embed locale-specific translations in the tests:
Check out implementation details of randomLocale and getTranslation here.
If your application uses a language selection menu, we advise writing a separate test case that asserts the application prompts the translations according to the user's choice. To mimic that behavior, one can leverage some randomness to keep the test case strong amongst supported languages:
Device Support and Responsiveness
Although the browser engine battle is long gone, your application may still target the broad population of modern devices with varying screen sizes and aspect ratios. Transpiling your frontend code to Browserslist default should suffice in terms of overall Javascript compatibility, but achieving a good User Experience (UX) throughout the various screen sizes can be a challenge.
If you need to assert your tests pass in specific browsers, most testing suites support that by customizing which one should be used to run your tests:
We want to guarantee that the application works as a black box, which means we check for inputs and outputs of the system. This testing approach helps ensure our applications work seamlessly in diversified scenarios for our users. To do this, we simulate rendering conditions by setting the viewport from a randomly chosen supported device before running any of our tests:
Tests that mimic user actions with interactive elements, such as cy.contains('button', 'Click me').click(), will automatically assert their visibility on the screen. Non-interactive elements that we wish to ensure are visible on the various screen sizes need to be imperatively tested:
Cypress will also account for the position of the element and try to scroll it into view before interactions are performed. Understanding how Cypress interacts with elements can be helpful to write consistent tests.
Happy and Unhappy Paths
Happy paths, or those in which the user completes the intended task, bring far fewer challenges than unhappy paths. However, these paths, which attempt to identify unknown variables, become time-consuming for developers—especially when their UI contains multiple interactive elements. Occasionally, we’ll disable the ones that might create a bad experience for our users or lead to inconsistent states, while other tasks are being performed in the background (e.g., waiting for an API response).
Developers can expand the concept illustrated in the example by asserting other common UI side effects tied to an API request, such as rendering overlays and loaders, performing redirects/routing, showing success or error messages, etc.
Sometimes unhappy paths are inevitable, like handling exceptions for instance. The way you choose to deal with them impacts directly on how to test these scenarios. The tests shouldn't care if you are using a React ErrorBoundary or an Angular ErrorHandler; they must assert what the user should be seeing if something goes wrong.
Multiple test scenarios may have the same outcome patterns, be it success or failure. You can leverage the testing tool to reuse assertions and make your test code leaner, just like how you would do to keep your application DRY (Don't Repeat Yourself principle).
Custom Cypress Commands allow developers to abstract patterns easily if repeated across many test cases. Besides assertions, the commands make it easy to perform repeatable user actions, like login, logout, changing roles, navigating to subareas of the system, filling out forms, etc.
Feedback Loops with Acceptance Tests
We’ve established the content and structure of acceptance tests, but writing acceptance tests don’t provide value on their own. Instead, we have to run them against the System Under Test (SUT) to create feedback loops to get the full value. At Basis Theory, we run acceptance tests at multiple points in the SDLC to provide meaningful feedback loops to detect bugs, regressions, and flakiness.
Developers should keep an eye out for test flakiness. Flakey tests can build up quickly throughout software lifecycle iterations if systems do not programmatically enforce thresholds in the pipelines. Thankfully, the internet offers plenty of resources to help write tests that avoid flakiness. In instances where we value failures over flakiness, we’ll occasionally dismiss test retries as a whole using a consistent environment between local development and pipeline runners.
Local Development
The fastest feedback loop is running the application on your local workstation when developing a new feature. We make use of Make (punny, I know) to run scripts that:
- Build the application
- Start and configure an ephemeral environment with dependencies
- Run acceptance tests
Using one command, make verify, we create an ephemeral environment and run all of our acceptance tests locally in minutes!
Pull Requests
Opening a pull request to the repository's default branch kicks off our CI pipeline. Thanks to automation, our pipeline uses the same make verify command to verify the code. The consistency between local development and our CI pipeline enables us to troubleshoot any failures in the pipeline without having to push new code.
Merge to Default Branch
Many debate whether to run unit and/or acceptance tests after merging to the default branch. Re-running these tests depends on how the CI/CD pipeline works.
If merging to the default branch promotes an immutable artifact built from the pull request workflow, re-running these tests may be redundant and costly. However, if merging to the default branch creates a new artifact, rerunning the tests might capture changes in the newly built artifact. Status checks and requirements in the CI/CD pipeline also play a factor. For example, if the pipeline doesn’t require acceptance tests to pass before merging to the default branch, acceptance tests need to be run before deploying to a live environment.
End-to-End Integration Tests
While Acceptance tests increase confidence that the UI works as expected, they don't ensure that the deployed application will function when connected to dependencies, such as an API. A common practice in SDLC asks QA folks to run regression tests on existing features and clients to perform User Acceptance Tests on deployed environments. End-to-End (E2E) integration tests don't fully replace these. Still, they do have the potential to push confidence and quality to similar levels, particularly if coming from a strong design cycle and agile feedback background.
E2E integration tests feel similar to UI Acceptance tests in setup. In fact, they often reproduce the same user interaction steps. However, they diverge in 3 fundamental ways:
- Focus on happy paths and replicate typical application use cases through a step-by-step user experience
- Run against deployed environments; not necessarily production, but as identical to it as possible
- Validate that the final user experience and all its moving pieces, such as external dependencies, work properly
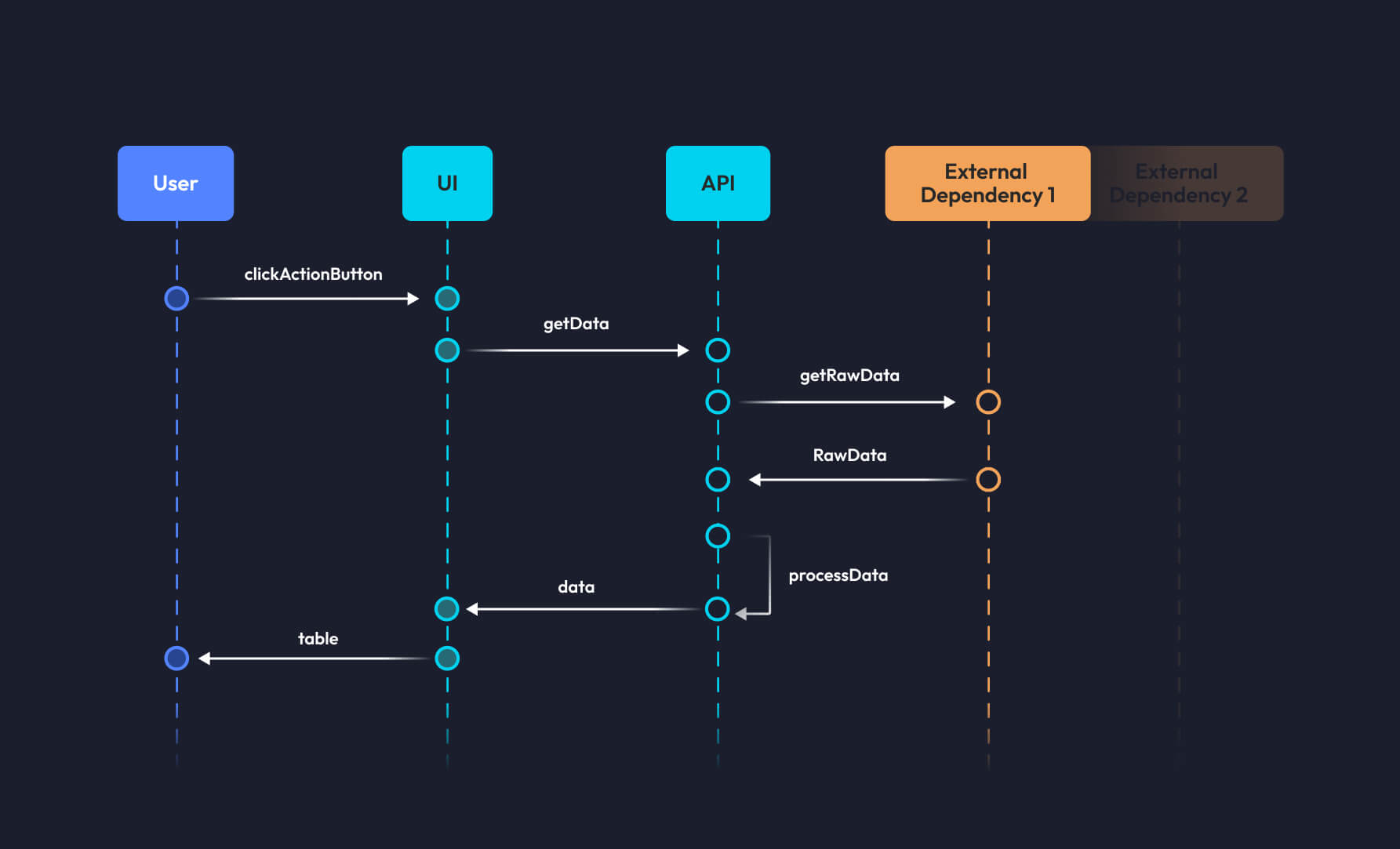
In practical terms:
- We now allow the requests to go through and hit the APIs, carrying back their real responses that once were stubbed using interceptions
- Injected user sessions in the browser are now replaced by actually typing username and password in the login form before moving to protected resources
- Timeouts are commonly increased, accounting for real-world usage scenarios
Configurable E2E Integration Tests
Configurable E2E tests enable faster feedback loops and debugging. In addition, when done right, we can run them against any environment. Even though they only increase confidence level when running against deployed environments, without the ability to configure E2E tests to point at a local environment we have no way to verify the tests work without merging them to our default branch and letting them run via automation.
Nonetheless, the configuration enables secure usage of applications and the organization of its secrets. When properly managed, pipelines can safely use sensitive data, like passwords, without the risk of leaking it.
Feedback Loops with E2E Integration Tests
So far, we’ve discussed our focus and configurability of E2E tests. Now let's see when we can run them to provide the best feedback loops in our SDLC and how they help bump that confidence level another notch.
After every deployment
After each deployment to our Development environment, our CI/CD pipeline runs the full suite of E2E tests. If a single test fails, the pipeline halts and blocks the promotion of the artifact to higher environments (e.g., Production).
On Demand
Since we can configure our E2E tests to point at any environment we have access to, we can run these tests whenever we like. We can run E2E tests from our local machine against a deployed Development environment or target a local ephemeral environment. This flexibility dramatically improves the developer experience when writing new tests or debugging a flaky test.
Pulse check: Confidence level
The goal of any test is to add confidence that the code, application, or system behaves as expected. So far, we’ve covered acceptance and Integration Tests, but how confident are we in our testing pyramid?
Are we confident that the application’s programmable interface does what we expect? Yes, the API Acceptance Tests provide this confidence by validating the system's behavior across various happy and sad-path scenarios.
Are we confident that the application can communicate with external dependencies? Yes, API Integration Tests provide confidence that our application can communicate and receive traffic from external dependencies in a deployed environment. E2E Integration tests cover the systems as a whole, replicating user behavior in a production-like environment.
Are we confident that the application’s user interface does what we expect? Yes. The UI Acceptance Tests give us confidence that the UI is behaving as expected.
Are we confident that the application is always available? Nope. Not yet.
Are we confident that the application can handle production throughput and beyond? Uh uh, not yet.
Are we confident that the application is free of security vulnerabilities? Also, not yet.
Are we confident that the application is secure against common attack vectors (e.g., OWASP)? Not yet.
Don't worry. By the end of this series, "Yes" will be the answer to all of the above questions. So stay tuned for our upcoming posts on the remaining testing layers, when to use them, and how they add confidence to our SDLC!
- Testing Layers and Principles
- API Acceptance and Integration Testing
- UI Acceptance and End-to-End Testing
- Synthetic Testing
- Load Testing
- Security and Compliance Testing
Have questions or feedback? Join the conversation in our Slack community!




